あふれる情報
この世界にはさまざまな情報源がある. 新聞,雑誌,テレビ,ラジオなどのマスコミや,書籍,Web,メールもある. 電話には固定電話と携帯電話がある.
我々は,これらの情報源から大量の情報をうけとっている. 新聞からの情報量として,リチャード・ワーマンによれば,「ニューヨーク・タイムズの平日版 の情報量は,17 世紀イギリスの平均的な人が人世の間に得るであろう情報量よりも多い.」 という (リチャード・ワーマン, 2001). またワーマンによれば,雑誌からは 「アメリカ合衆国では,毎年およそ 9600 種のさまざま な定期刊行物が発行されている.」 という (ワーマン, 1989). 日本の雑誌についてみると,9700 種くらいの雑誌があるという (http://www.ndl.go.jp/jp/data/sakuin/sakuin_index.html). 近年,日本ではフリーペーパーがひろく配布されるようになっているが,これは 500 種くらい (http://www.freepapernavi.jp/) あるようだ.
メールについてみると,ワーマンはつぎのようにいっている. 「電子メッセージング協会の試算では,今年 1 億 800 万人のユーザーが 7 兆通以上の電子メールを受け取ることになる.あなたも含め,1 人当たり約 6 万 5000 通の計算だ.」 (ワーマン, 2001)
ワーマンはこういう情報の全体を歴史的に比較して,「最近 30 年間に生産された情報のほうが,それ以前の 5000 年の間に生み出された情報よりも多い.」 といっている (ワーマン, 1989).
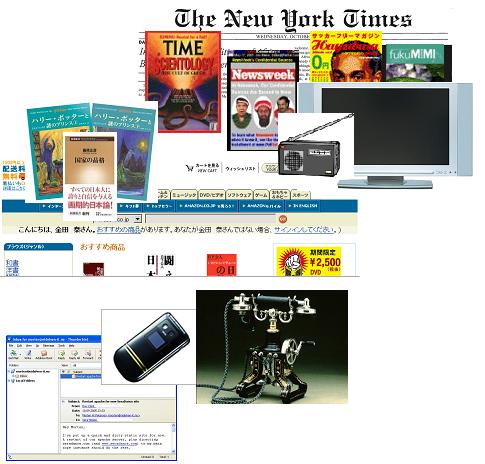
図 さまざまな情報源とあふれる情報
 ほしい情報をうまく知覚できるようにするには,つぎの 2 つの操作をあわせてつかえばよい.
ほしい情報をうまく知覚できるようにするには,つぎの 2 つの操作をあわせてつかえばよい.
 Yahoo は現在では検索エンジンをそなえ,またポータルサイトの顔をしているため,本来のすがたがみえにくくなっているが,本来は Web のディレクトリ検索を実験したものである.
右の図は Yahoo がまだこの本来のすがたをはっきりとしめしていた時期のものである.
つまり,その基本は人手で WWW 上の情報を分類してディレクトリをつくることが目的だった.
現在でもそれがひきつがれている (現在はどこがちがうか?).
Yahoo は現在では検索エンジンをそなえ,またポータルサイトの顔をしているため,本来のすがたがみえにくくなっているが,本来は Web のディレクトリ検索を実験したものである.
右の図は Yahoo がまだこの本来のすがたをはっきりとしめしていた時期のものである.
つまり,その基本は人手で WWW 上の情報を分類してディレクトリをつくることが目的だった.
現在でもそれがひきつがれている (現在はどこがちがうか?).
 また,分類項目からの検索とならぶ方法として,テキストからの検索がある.
Google (右図参照) によって代表されるのがこれである.
つまり,Google においては Web におけるキーワード検索が実現されている.
この方法においては “機械的” に Web 情報のインデクスをつくり,それをつかって検索する.
また,分類項目からの検索とならぶ方法として,テキストからの検索がある.
Google (右図参照) によって代表されるのがこれである.
つまり,Google においては Web におけるキーワード検索が実現されている.
この方法においては “機械的” に Web 情報のインデクスをつくり,それをつかって検索する.
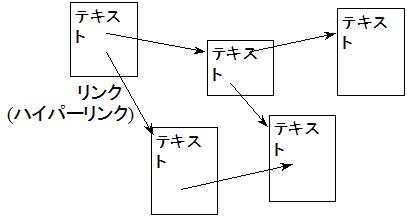 もうひとつの方法としてハイパーテキスト検索がある (右図参照).
ハイパーテキストとは複数のテキストをリンク (ハイパーリンク) でむすびつけ,リンクをたどりながらテキストをよむことができるようにしたものwである.
リンクをたどることによって,目的のテキストにすぐアクセスすることができる.
たとえば,WWW のリンクをたどるのがこの方法である.
(ディレクトリ検索に似ているが,ちがう.
どこがちがうか?)
もうひとつの方法としてハイパーテキスト検索がある (右図参照).
ハイパーテキストとは複数のテキストをリンク (ハイパーリンク) でむすびつけ,リンクをたどりながらテキストをよむことができるようにしたものwである.
リンクをたどることによって,目的のテキストにすぐアクセスすることができる.
たとえば,WWW のリンクをたどるのがこの方法である.
(ディレクトリ検索に似ているが,ちがう.
どこがちがうか?)
