 ]]>
]]>
]]>
]]>
SFF シンポジウム 2013 で “A Method of 3D Printing which is Consistent with Natural Direction in Shape” というタイトルのポスターを発表した. そのポスター はそれだけでは十分に説明的でなかったのと,英語で書いていたので,ここに日本語版をのせる.
]]> 要旨: 3D プリンタで印刷するときは,通常,物体を水平にスライスする. そのため,もしその印刷する物体が繊維のあつまりのように,その本性において自然な方向をもっているときには,印刷の方向が自然な方向と矛盾することになる. ここで提案する 「場指向の 3D 描画ソフトウェア」,「場指向のソリッド・モデラ」,「場にもとづくツールパス生成ソフトウェア」,「非水平型の熱溶解積層型 3D プリンタ」 などの適切なツールをつかうことによって,自然な方向をモデル化し,物体をその自然な方向にそって印刷することができるとかんがえられる. この目標を達成するために,まだ全部ではないがいくつかの設計・製造上の問題を解決した. この方法の応用として (日本風の) 3D 書道がある. もとのポスター繊維のあつまりのような物体を印刷するとき,その物体のかたちには 「自然な方向」 がある (図 1 参照). 葉は 「自然な方向」 にしたがう葉脈をもっている. ひとの髪の毛や,中国や日本の書道作品の各部分も 「自然な方向」 をもっている.

図 1. 自然な方向をもつかたち
しかし,最近,普及価格帯の 3D プリンタとしてひろくつかわれるようになっている熱溶解積層法 (FDM, fused deposition modeling) による 3D プリンタでは,印刷の方向は 「自然な方向」 と矛盾しがちだ. なぜなら,それらの 3D プリンタではヘッドを常に水平に移動しながら印刷するからである. この矛盾はいわゆる 「階段効果 (staircase effect)」 をもたらして,印刷した物体のかたちを不適切なものにし,いきおいをなくしてしまう (図 2 左参照). この物体のかたちは,図 2 の右のようであるべきだ.
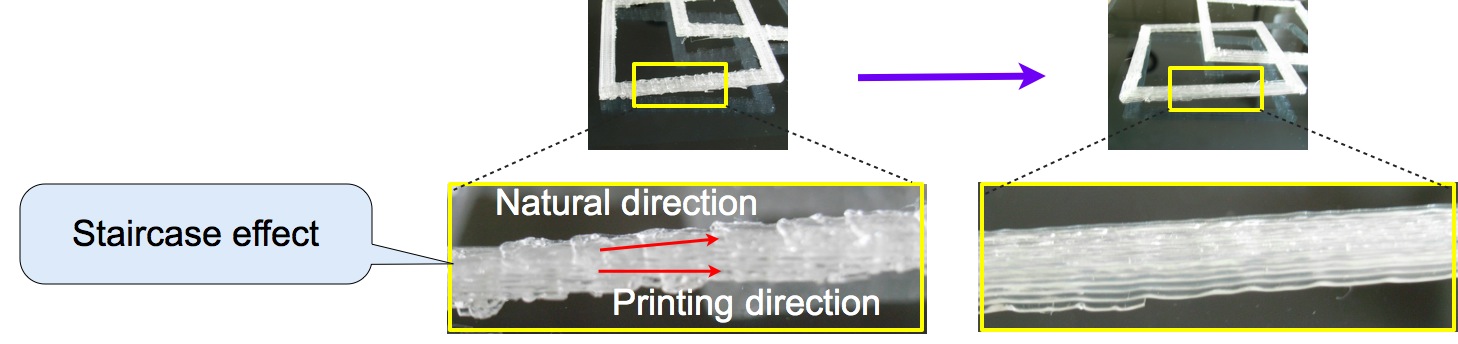
図 2. 印刷方向 対 自然な方向
上記の問題を解決するため,「場」 にもとづく解決策を提案する. 提案する方法では,物体を 「自然な方向」 をいかしてモデル化し,「自然な方向」 にスライスし印刷するために,つぎの 3 つのステップにしたがって物体をデザインし印刷する (図 3 参照).
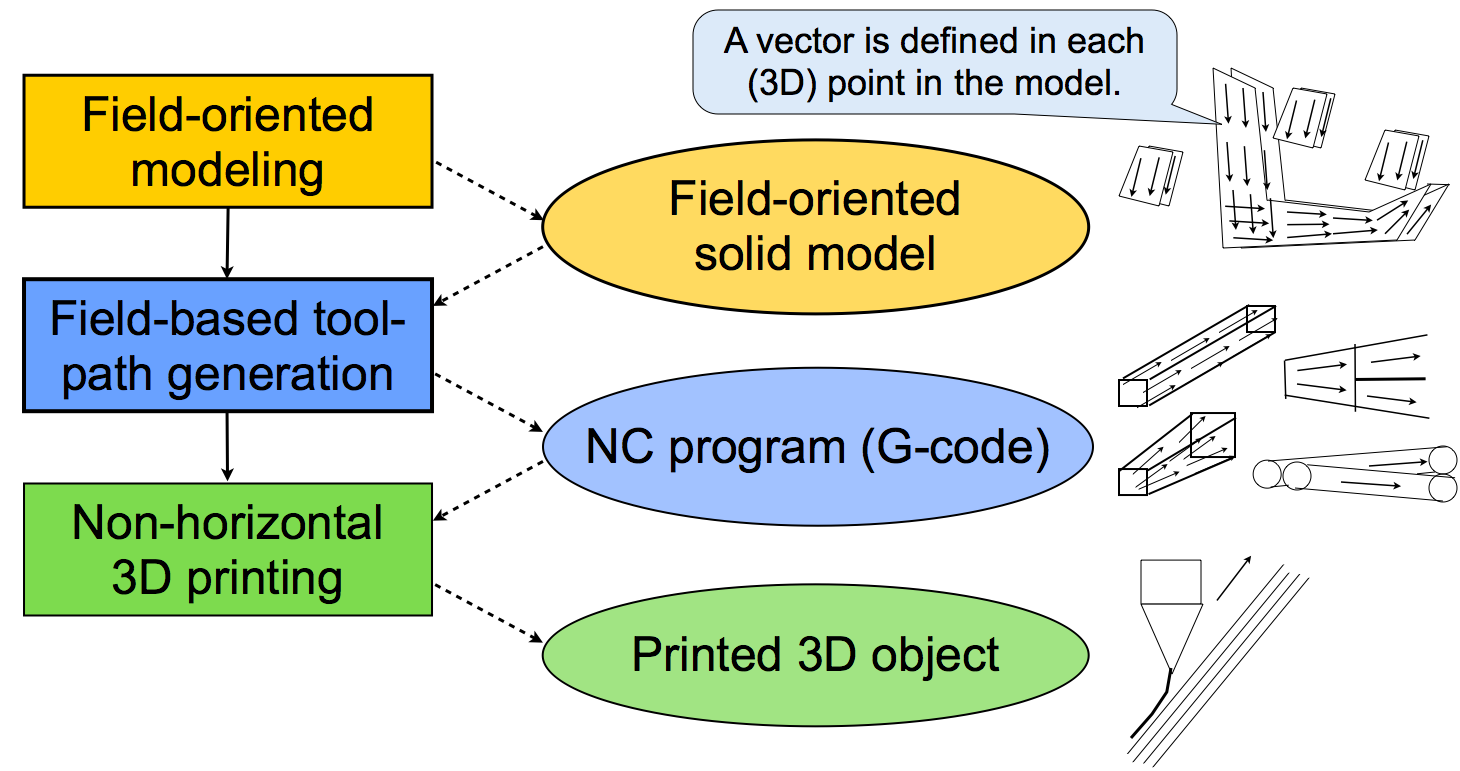
図 3. 自然な方向の 3D 印刷のための 3 つのステップ
場指向モデリングは,従来のソリッド・モデルを拡張した 「場指向ソリッド・モデル (field-oriented solid model)」 を出力する. このモデルの各点 (3 次元の点) では,図のようにベクトルが定義されている.
場にもとづくツールパス生成においては,場指向のソリッド・モデルを入力し,G コードのような通常の NC プログラムを出力する. このツールパス生成のアルゴリズムは従来の 3D 印刷における 「スライス」 のアルゴリズムとは完全にことなる.
非水平型 3D 印刷においては,自然な方向にしたがって物体がつくられる. G コードは水平でない動作を記述することができ,従来の 3D プリンタはそれをただしく実行することができるので,このプロセスは従来の 3D プリンタであつかうことができる.
つづく 3 つの節においてこれらのステップを説明する.
場指向モデリングのための 2 つの方法を提案する. それらは,場指向 3D CAD と場指向 3D 描画である.
場指向 3D CAD のための 2 つの方法を提案する. そのひとつは,図 4 にしめす 「部品結合法」 である. この方法では,設計者は 3 次元の 「場」 つきの部品を場指向 3D CAD ツールをつかってくみあわせる. くみあわせの操作は通常の和 (union),積 (intersection),差 (difference) などにもとづいている. しかし,これらの操作は部品がもつ場からくみあわせた結果の場をもとめる方法を定義していなければならない.
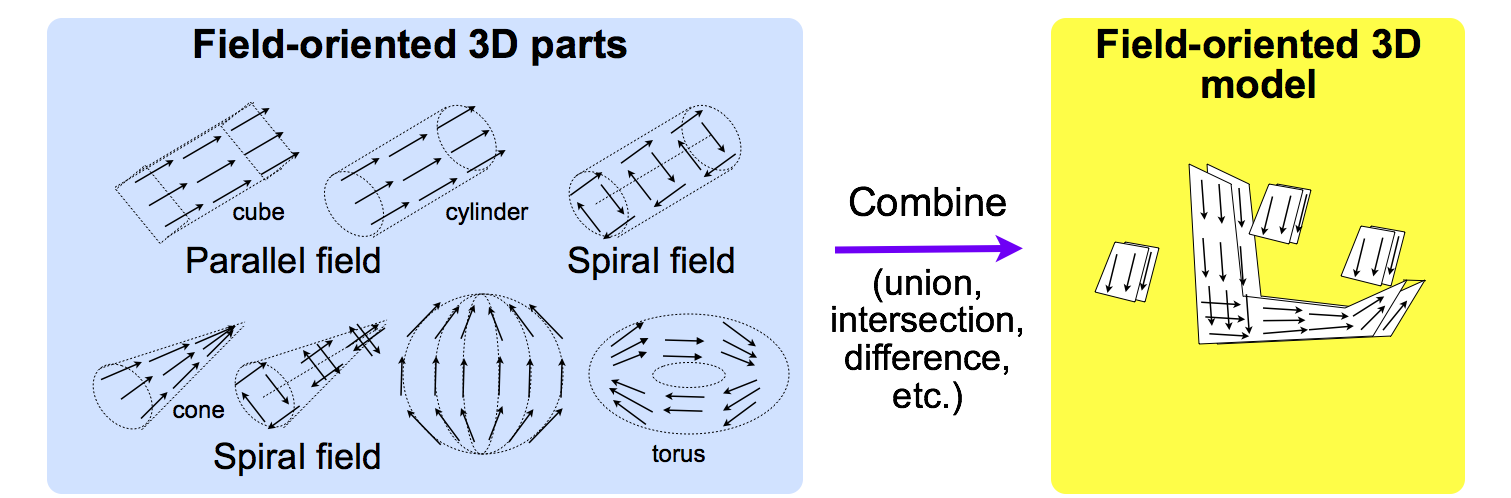
図 4. 場指向 3D CAD における部品の結合
もうひとつの方法は,図 5 にしめす 「磁化」 である. この方法では,設計者はまず通常の 3D ソリッド・モデルを従来の 3D CAD ツールをつかって設計する. そして,設計者が選択した場のなかに設計した物体をおく. 設計者が 「場のコピー」 の操作をすると,場が物体にうつしとられる.
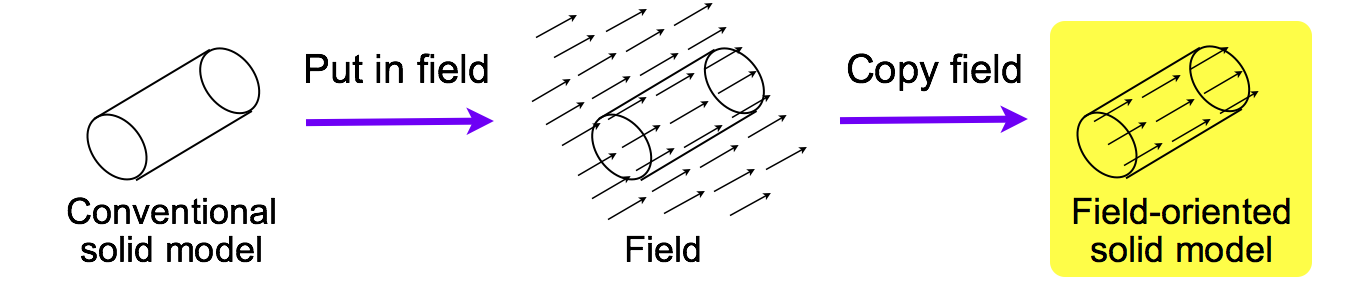
図 5. 場指向 3D CAD における 「磁化」
「場指向 3D 描画」 は,パソコンでひろくつかわれている 2 次元の描画 (ペイント) に類似している. 2D 描画ツールで 2 次元のポインティング・デバイスをつかうのと同様に,3D 描画ツールでは 3 次元のポインティング・デバイスをつかう (図 6 参照). 3D ポインティング・デバイスとしては,人体を追跡 (トラッキング) する Microsoft Kinect のようなデバイスや,加速度センサーを搭載した任天堂 Wii のようなデバイスを使用することができる. 人体を追跡するときは 「3 次元ブラシ」 のようなかたちで描画ツールの幅とかたちを人の手 (指) で指定することができる. また,加速度センサーによるときは圧力センサーなどでそれらを指定することができる. 通常の描画ツールとはちがって,場指向 3D 描画ツールは移動方向も記録し,えがかれた物体 (軌跡) の各点の場のベクトルを定義する.
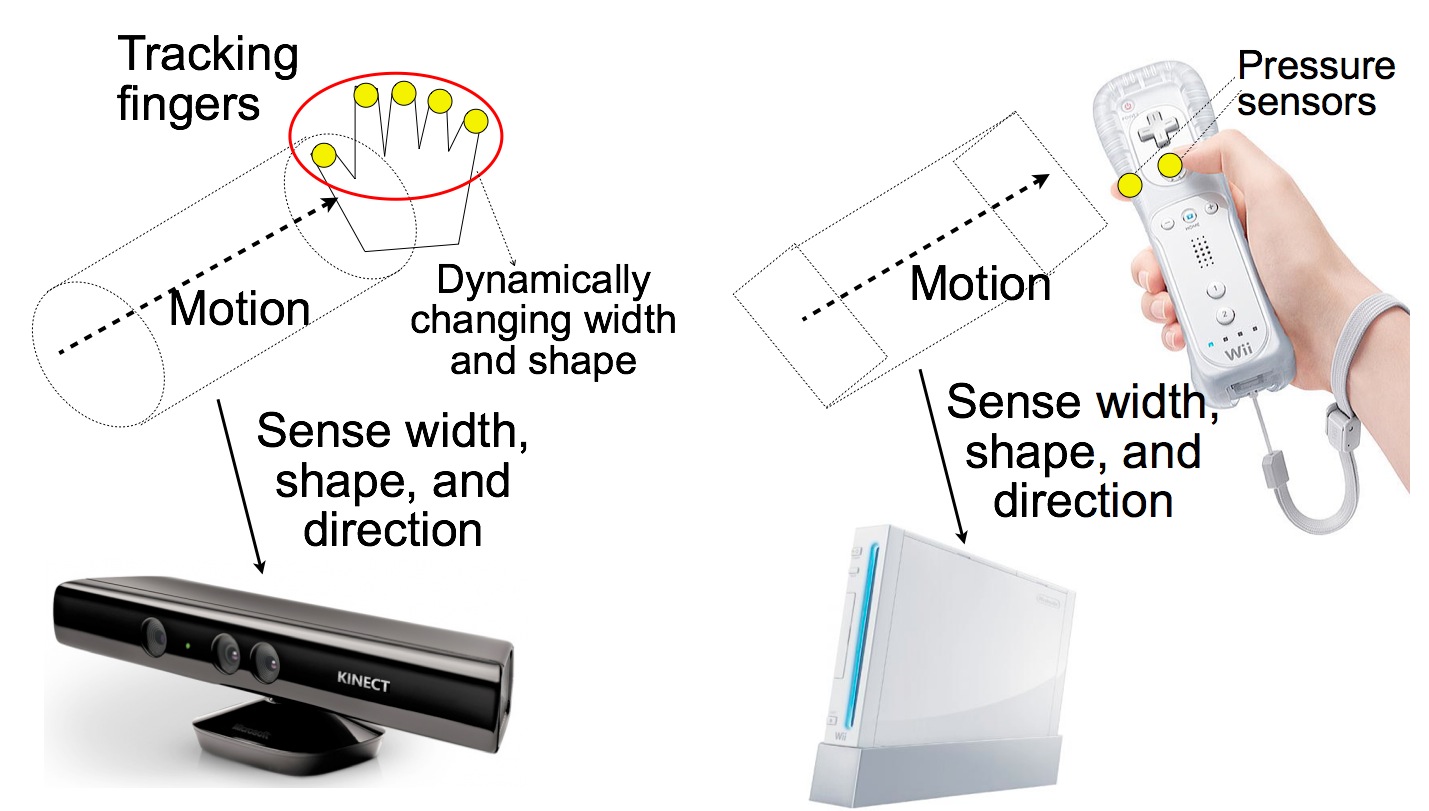
図 6. 場指向 3D 描画
3D プリンタのためのツールパスは 4.1 節に記述する基本的な方法によって生成する. いくつかの補足的な技術を 4.2 節でしめす.
このツールパス生成法では,物体 (モデル) は図 7 にしめすように場のベクトルにそって 「ハッシュ」 される. このプロセスは,場のベクトルが並行でないときには従来の 3D 印刷における 「スライス」 とはまったくことなる. もし物体が図 7 の左にしめすように平行な場をもつときには,モデルをハッシュしてできた 「糸」 はフィラメントを一定におしだすことによって容易にみたす (うめる) ことができる. しかし,もし場のベクトルが平行でなければ,図 7 の右にしめすように,糸をひろげたり (widening) せばめたり (narrowing) する必要がある. このような場合には,糸をみたすために,おしだすフィラメントの量を増加させたり減少させたりする必要がある. しかし,もしベクトルが平行からおおきくはずれているときには,補助的な方法が必要である. そのような状況でつかえるいくつかの技法をつぎの項で記述する.
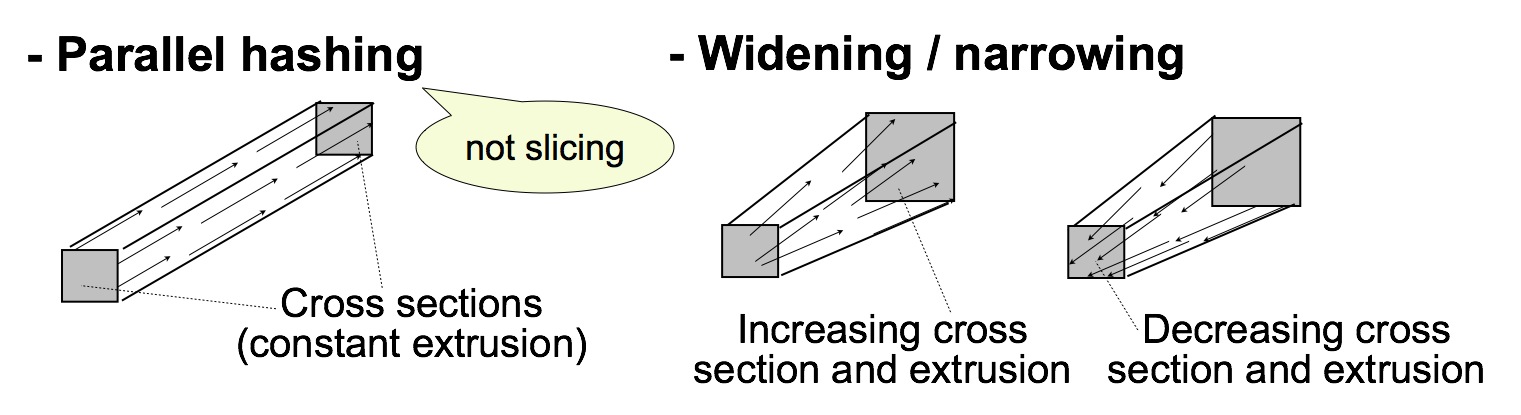
図 7. 場にもとづく基本的なツールパス生成法
糸の断面が印刷方向にむかって急速に変化するときは,図 8 にしめすように,糸をわけたり (splitting),あわせたり (merging) する必要がある. 図 8 にいれた写真が,Printrbot Plus という 3D プリンタで印刷した,糸をわけたりあわせたりする 2 つの例をしめしている. 糸が縦方向にはひろがり水平方向にはせばまっているとき,あるいはその逆のときには,「ねじり (twisting)」 という方法を適用することができる (図 8 の右を参照).
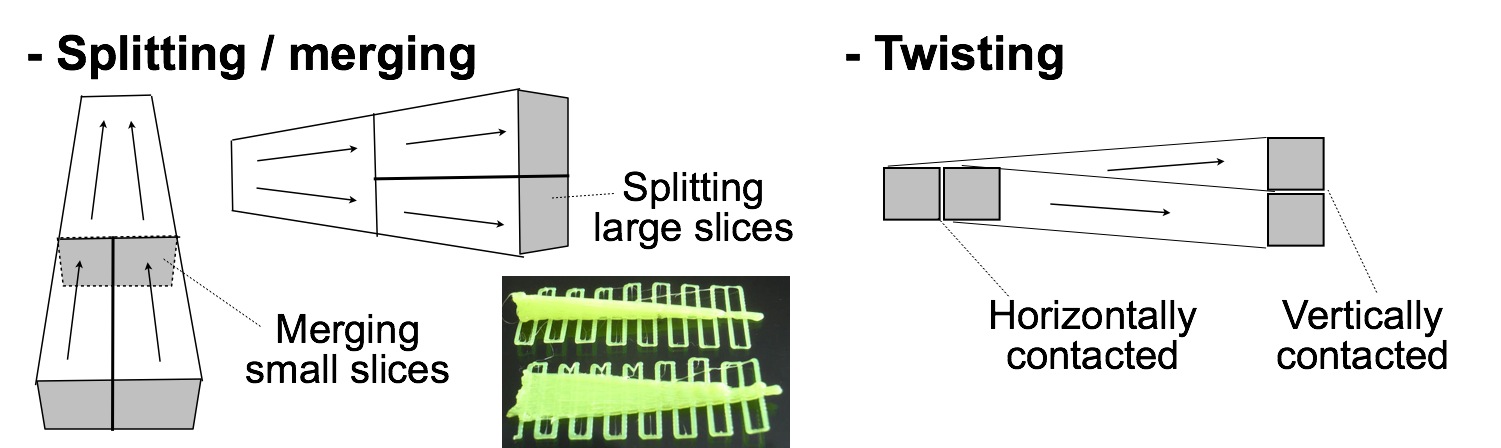
図 8. 場にもとづくツールパス生成の技法
従来の CNC と同様に,物体のかたちによっては 3D 印刷によって造形することができない. 印刷可能な物体の範囲は,従来の 3D 印刷より自然な方向の 3D 印刷のほうがせまい. しかし,その範囲は印刷順序の変更によってひろげることができる.
図 9 にひとつの例をしめす. 左上の図はもとのかたちをしめす. これは 2 個の輪からなるチェーンであり,このままでは印刷不能である. そのうちの 1 個の輪を 2 つに分割して右上のように印刷順序を変更すると,印刷可能になる. 図の下の写真はこのチェーンの四角形版の実例をしめしている. これは自然な方向に印刷したものである. このようなツールパスを生成するツールはいまのところないので,このチェーンのためのツールパスは専用のプログラムによって生成している. 左の写真はこのチェーンの 3 番めの部品をしめしている.
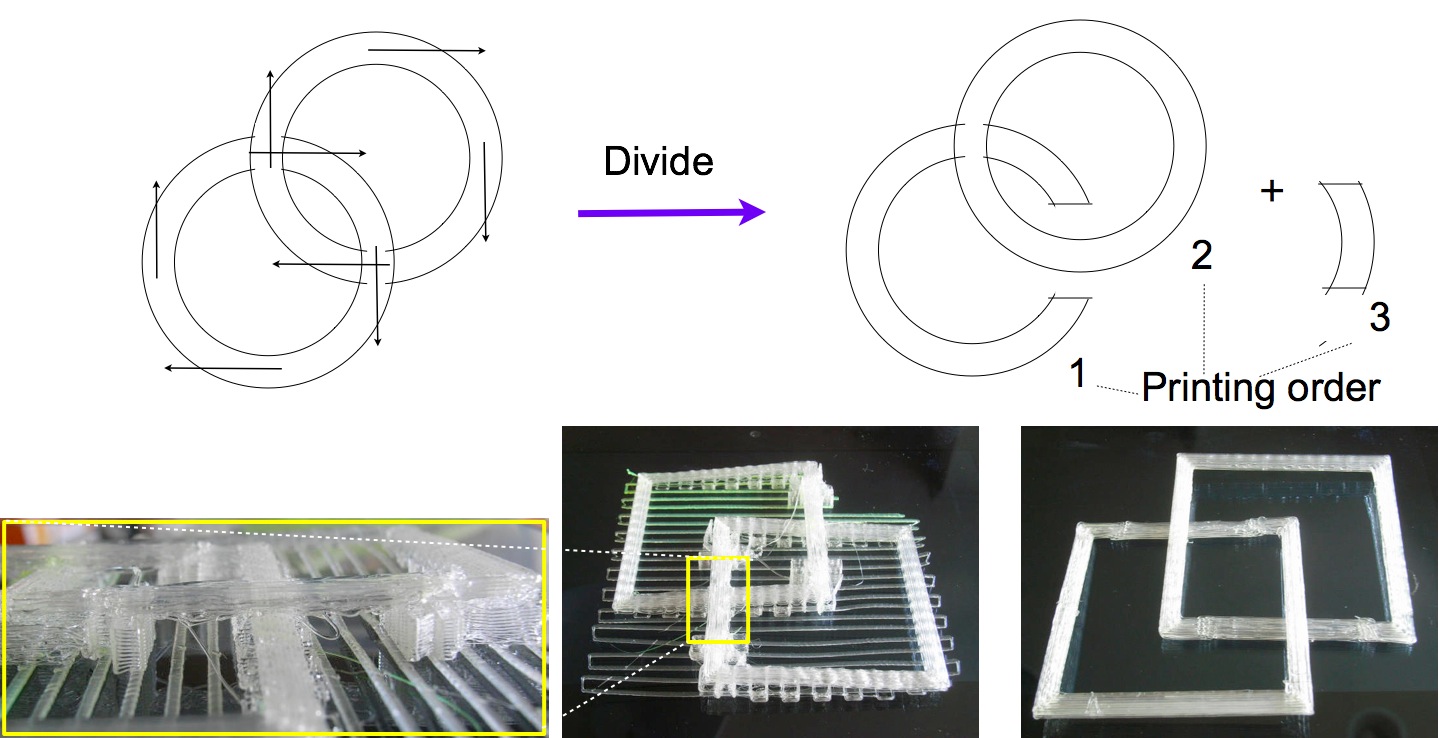
図 9. 印刷不能な物体の印刷可能化の方法
通常の 3D プリンタは自然な方向の 3D 印刷のための G コードを処理することができる. しかし,それらで急角度の印刷をすることはできない. この節においては,問題点とそれをふせぐための印刷技法について記述する.
急角度の印刷を困難または不可能にしている 2 つの問題がある (図 10 参照). ひとつの問題は,従来の 3D プリンタで急角度に移動しながら印刷すると,印刷中の物体に衝突してしまうということである. すなわち,従来の 3D プリンタは 3 軸の工作機械であり,底面からだけフィラメントをおしだすからである. このような衝突をさけようとすると,ノズルを印刷物に十分ちかづけることができなくなる. つまり,ノズルの先端と印刷物とのあいだにすきまができる.
もうひとつの問題は,従来の 3D プリンタは通常,垂直方向 (z 軸方向) の移動のためにネジをきったロッドをつかっているため,その方向にすばやく移動することができないということである.

図 10. 急角度の印刷の問題点
より深刻な最初の問題を解決するには,2 つの方法がつかえる. ひとつの方法は針のような形状のノズルを使用することである. 図 11 の左にこの方法を図示した. もしノズルの先端が針状であれば,急角度の印刷が可能になる. しかし,このような形状では先端の温度の低下が問題になるだろう. 温度をたもつためにいくつかの方法がつかえる. ひとつの方法は,図にしめしたように先端を断熱材でおおうことである. 針状のノズルによって急角度の印刷ができるようになるが,それでも垂直に印刷することはできない. しかし,この方法は従来のプリンタの改良によって実現できるという利点がある.
他の方法は 5 軸 (または 6 軸) のヘッドを使用することである. ヘッドを回転させるために 2 つ (または 3 つ) の軸を使用する. これによって,回転させたヘッドで垂直に,あるいは下面に印刷することが可能になる. しかし,このようなプリンタはほとんどスクラッチから開発する必要がある. Xuan Song ら [1] はこの型の 3D プリンタを開発している. しかし,回転角は制限されている.
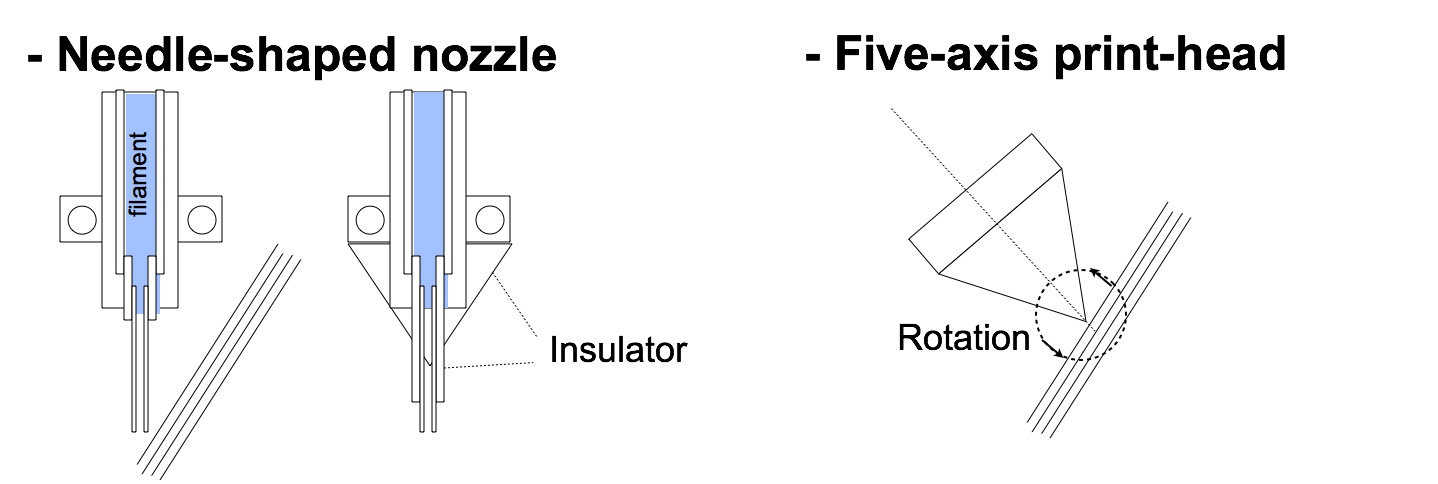
図 11. 急角度の印刷の問題の 2 つの解決策
2 番めの問題の解決策については 6.3 節でのべている.
自然な方向の 3D 印刷技術の実装はまだ非常に初期の段階にある.
3.2 節で提案した Kinect にもとづくモデラを設計中だが,まだ実装していない.

図 12. Microsoft Kinect
ハッシング・アルゴリズムを部分的にテストしている状態である. 4.3 節に記述した印刷可能性の改良の方法をテストしているところを,図 13 左の写真はしめしている. 中央の写真は分割 (splitting) とマージ (merging) をふくむ印刷物をしめしている. 右の写真は,応用の節で説明されるべき,3D 書道のためにハッシュされテスト印刷された物体をしめしている.

図 13. ハッシング・アルゴリズムのテスト
非水平型印刷法はこれまで Printrbot Plus という 3D プリンタを使用してテストし,現在は Rostock MAX という 3D プリンタ (図 14 参照) を使用してテストしている. Rostock MAX はデルタ型 3D プリンタのひとつであり,ヘッドを高速に z 軸方向に移動させることができる. それゆえ,このタイプのプリンタは 5.1 節でのべた第 2 の問題を解決することができる.

図 14. 印刷法と技法のテストに使用した 3D プリンタ
3D 印刷は工業的な応用,とくにラピッド・プロトタイピングにつかわれてきた. しかし,自然な方向の 3D 印刷の技術の主要な応用はそれとはちがうタイプのものであるかもしれない.
自然な方向がより重要なのは芸術的な応用だろう. この項では 3D 書道への応用に焦点をあてる. 図 15 の左の写真は (ほぼ) 方向のない (わからない) 3D 書道作品である. 右の写真は方向のある 3D 書道作品である. 鉄を使用したこのような作品がすでに製作されている. 自然な方向の印刷はこのような方向のある 3D 書道に応用できるとかんがえられるが,まだ適用されてはいない. この図は日本の書道家である紫舟 (Shishu, Sysyu) による作品をしめしている.
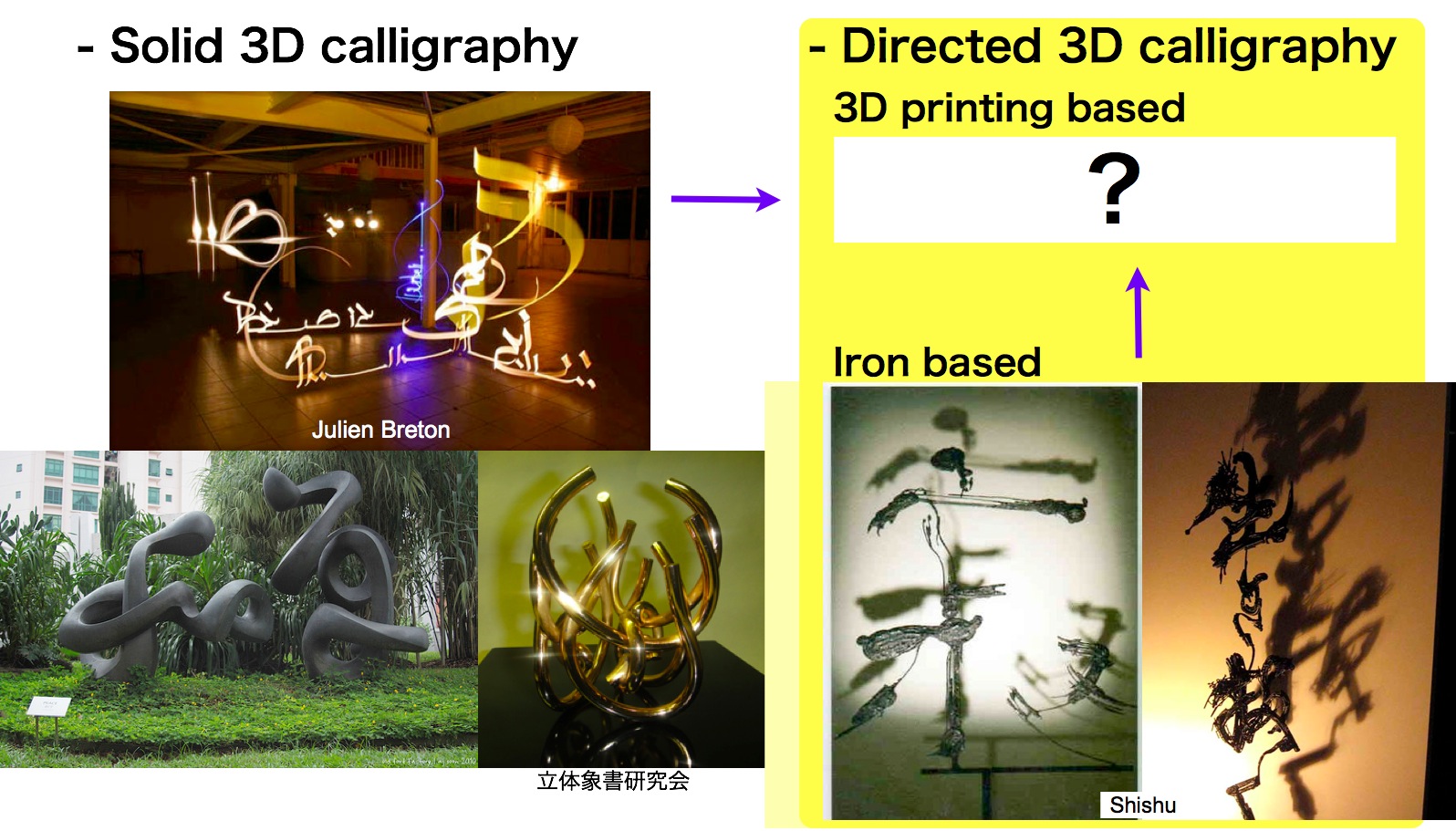
図 15. 3D 書道への応用
最近,安価な FDM 3D プリンタがホビイストによってつかわれている. たとえば,しばしば印刷されている図 16 のピラミッドや多面体は,自然な方向の印刷法によってよりよく印刷できるかもしれない.

図 16. 趣味への応用
工業的な応用もあるだろう (図 17 は従来法の応用) が,有力な応用はまだわからない.

図 17. 工業的な応用?
このプレゼンテーションはつぎのようにまとめられる.
場指向のモデリング,場にもとづくツールパス生成法,そして非水平型 3D 印刷法は開発されつつあり,それらはアプリケーションそのなかでも 3D 書道に最初に応用されようとしている.
[1] Xuan Song, Yayue Pan, and Yong Chen, “Development of a Low-Cost Parallel Kinematic Machine for Multi-Direction Additive Manufacturing”, SFF Symposium 2013.
]]>こういうプログラマビリティの実現や仮想化は,その後のコンピュータの歴史のなかで,かたちをかえて何度もくりかえされてきました. そして,いま,またネットワークにおいてくりかえされようとしています.
]]> 私にとってコンピュータの出現や記憶の仮想化などは歴史的なできごとであって,私自身はそれを経験したわけではありません. しかし,私はスパコン (ベクトル・プロセッサ) の開発のなかで,ある意味で歴史が逆行するのを経験しました. スパコンにおいては処理が高速であることがまず重要であり,そのために初期のスパコンにおいては仮想記憶が犠牲にされました. しかし,スパコンにおいてもそれが必要なくなったわけではないので,まもなく再度とりいれられることになりました. ただし,スパコンに関しては最初からプログラミングには高級言語すなわち Fortran がつかわれました. そうでなければ売れないとかんがえられたからでしょう.IP ネットワークにおいては,ネットワークを構成するためにルータがつかわれます. ルータはもともと汎用コンピュータだったのですが,ネットワークのために専用化され,プログラムすることはできなくなってしまいました. ここでもある意味の逆行がおこっています. しかし,10 数年まえからプログラマブルなネットワークつまり 「アクティブ・ネットワーク」 をつくろうといううごきがでてきました.
また,ネットワークをユーザやネットワーク・トラフィックごとの 「ポリシー」 によって制御しようという 「ポリシーベース・ネットワーキング」 はすでにある程度,実用化されています. この世界ではポリシーはプログラムだとはかんがえられていませんが,私はポリシーをプログラムと同様のしくみで部品からくみたてるしくみを提案してきました.
「アクティブ・ネットワーク」 のほうはまだ実用化されているとはいえませんが,最近では PlanetLab, GENI, Akari などのプロジェクトによってそれが加速されるようになってきました. 私自身もいまそういうなかにいます.
コンピュータが登場したときと同様に,アクティブ・ネットワークやポリシーの実現のために,まずプログラマブルなルータがつくられました. このプログラマブルなルータにおいて,スパコン開発におけるベクトル・プロセッサに相当するものがネットワーク・プロセッサです. ネットワーク・プロセッサはネットワーク・トラフィックを高速に処理できる性能とプログラマビリティをあわせて実現しています. しかし,いまのところは機種依存のアセンブリ言語や特殊な C 言語が使用されていて,いわゆる高級言語によってプログラムを記述できるようにはなっていません. また,高速処理のために仮想化機能を犠牲にしています. つまり,仮想化に関してはベクトル・プロセッサのときとおなじみちをたどっています.
そしてつぎには,やはりベクトル・プロセッサのときとおなじように,このプログラマブルなルータを複数のユーザが仮想化してつかえるようにしようということになってきました. いずれネットワーク・プロセッサが仮想化機能をもつようになるかもしれませんが,いまはそれがつかえないので,Multics 以前のやりかたをつかわざるをえません. 当時は仮想化のハードウェアがなくてもソフトウェアでくふうすれば,ユーザ間の干渉をなくせるということが主張されていました. そういう手法をネットワーク・プロセッサにもとづくルータにとりいれることができます. また,当然のことながら,ネットワーク・プロセッサにおいて高級言語がつかえるようにする研究もさかんにおこなわれています. そこではベクトル処理や並列処理のためのコンパイラにおけるのと同様に,最適化が重要な課題になっています. 当時とはいろいろちがうところもありますが,やはり歴史がふたたびくりかえしているという印象です.
]]>また,voiscape においてもとめてきたのは 「みとおし (ききどおし?) のよいコミュニケーション」 でした. 電話や会議システムのような従来のコミュニケーション・メディアにおいては,それをつかっておこなわれる会話はみとおしのわるいものになってしまいます. 電話であれば基本的には 1 対 1 でつながるだけなので,第 3 者にとってはその会話はまったく認知できないか,または,会話しているふたりのうちのひとりに物理的にちかい場所にいればそのひとりの話がきこえるだけなので,いずれにしても,それがそのひとにとって関係のある会話であっても,みとおしのわるいものになってしまいます. また,会議システムも閉じた会話のためのメディアなので,立ち話やカクテルパーティのように第 3 者がはいりこめる余地はありません. 第 3 者にとっては,会話の内容はおろか,会話がおこなわれていることを知るのも困難です. こういうみとおしのわるさを (なくすとまではいえませんが) へらすため,voiscape においてはひとつの部屋のなかで複数の会話が同時進行できるしかけをつくっています.
また,軸づけ検索や voiscape におけるのとはかなり意味はちがいますが, CCM においては通常の論理にもとづく計算のみとおしのわるさを解決するために,エネルギーが最小化する方向に計算がすすむようなしかけをとりいれています (CCM では 「エネルギー」 ではなく 「秩序度」 ということばをつかっていました). 論理にもとづく計算ではちょっとしたバグのために計算がとんでもない方向にすすんでしまう (暴走する) ことが容易におこりますが,最小化のしかけをいれることによってこういう事態をふせぐ意図がありました. ただし,このような最小化のしくみをとりいれた計算モデルとしては,ニューラルネットや遺伝的アルゴリズムが有名であり,ほかにもおおくの計算モデルがあります.
CCM における 「みとおしのよい計算」 はべつとして,軸づけ検索や voiscape における 「みとおしのよさ」 はユーザからみえるものであり,デジタル・コンピュータをつかったコミュニケーションや計算が本質的にかかえている問題点を部分的ながらも解決しようとしています (この問題点は,いまはうまく説明できませんが,おそらく私が 「ライフワーク」 と呼んだ“デジタルとアナログの融合” や “記号と記号下のものの融合” と関係しているものとおもいます). Web や携帯電話やその他のデジタル・メディアからおこっている問題のおおくがここに起因していると私はかんがえています. したがって,それを解決することは現代社会がかかえる問題への解決策を模索することだとかんがえています.
こう書くといささかおおげさにひびくかもしれませんが,技術的な問題解決なしにデジタル・メディアがうみだす社会問題の解決はできないようにおもいます. つまり,現在の携帯電話は集中制御型のシステムなので,規制することによって問題がおこらないようにすることはできるかもしれませんし実際に日本政府による規制がはじまっていますが,インターネットのような分散制御型のシステムにおいてはうまく規制することができないとおもえます. みとおしのよさをのぞまないひとをこういうしかけのなかにとりこむのは困難ですが,それでも,みとおしをよくすることによって,ある程度は解決できるものとおもいます.
]]>2006 年度の成果はすでに研究会論文などに書きましたが,それらについてはブログの 「デジタル音声再生は,ひとすじなわではいかない」 という項目にも書きました. 来年 1 月には ICOIN 2008 という,釜山でひらかれる国際学会でも発表することになっています. しかし,個々の論文に書いたことはこの 1 年間にやったことの一部でしかありません. 1 年間でいったい,なにをやろうとしたのかという,それらの論文にまたがることは,論文には書く場所がありません. それは国プロの報告書には書いてよいはずのことですが,3 月ぎりぎりまで実験をしていたので,ゆっくりふりかえって書く時間もなくて,書かずじまいになってしまいました. また,もし仮に国プロの報告書に書いてあったしていも,それにふれるひとはすくないので,もっとひとの目にふれるこの場所で書いてみようというわけです.
プロジェクトは 2005 年度からスタートしていますが,この年には私は担当していませんでした. したがって,私にとっては 2006 年度が初年度でした. このプロジェクトではポリシーにもとづく NGN 的な意味でのネットワーク QoS の制御 (資源とアドミッションの制御) がテーマになっていました.
QoS に関しては多数の論文が出版されていますが,そのなかには理論的な論文やコンピュータ上でのシミュレーションにもとづく論文がおおく,実際にバックボーンでつかえるような機器をつかったネットワークに実際にトラフィックをながして測定・評価した論文はすくないのです. また,実際に測定をおこなっている場合でも,比較的小型のルータやスイッチを使用して,トラフィック量も 100 Mbps 以下のことがおおいのです.
精密なシミュレーションをおこなえば実際に測定しなくてもわかるということかもしれませんが,現実のネットワーク機器やサーバが理論どおりに動作するとはかぎりません. バグがあればもちろんですが,そうでなくても理論からずれてくる可能性はいろいろかんがえられます. したがって,この仕事をはじめるにあたって,私は実際の機器とプログラムとを使用して実測にもとづいて評価したいと,つよくおもいました.
また,QoS というのは最終的には通信をおこなうユーザがその品質に満足するかどうかで評価するべきものなので (そういうときには QoS というよりは QoE (Quality of Experience) ということばがつかわれますが),上記のような客観的な評価だけでなく,被験者をつかっての主観的な評価までやりたいとおもいました. 会社の仕事ではなかなか主観評価にまで予算を用意することがむずかしいのですが,国家プロジェクトの利点はそこまで予算がかけられることです. その利点をぜひ,いかしたいとおもいました. 主観評価のためによくやる方法は社員をかきあつめてきて自分で実験するというやりかたですが,そうしなかったのは第 1 には私自身は経験がないのでそういうやりかたではうまくやれる自信がなかったし,ひとりで実験できるともおもえなかったからです. また第 2 には社員をあつめればみかけ上はコストがかからないのですが,実は時間給を計算すれば非常にたかくつくからです.
そういうわけで,今年 2 月までにプログラムを開発して実験用のネットワークを組み,3 月には客観評価と主観評価とをおこないました. 先端的なルータをまとまった期間借りるということはなかなかできなかったので,GS4000 というハイエンドの L3 スイッチを借りました. それも 1 台だけしか借りられなかったので,くふうして実験用ネットワークを組みました (そのために結果の透明性が低下して,国際学会への投稿でも評価がさげられる原因になってしまったのですが…).
また,バックボーンでつかえる技術をめざした開発なのでほんとうは 10 Gbps のリンク (10 ギガビットのイーサネット) をつかって実験したかったのですが,断念しました. というのは,のぞみの性質をもった 10 Gbps のトラフィックをうまく発生させられる自信がありませんでした. そのため,1 ギガビットのイーサネットを使用し,3 台の PC を使用して MMPP (Markov-Modulated Poisson Process) というモデルにしたがう 1 Gbps 程度のトラフィックを発生させて実験しました. この MMPP というモデルはシミュレーションにおいてはよくつかわれているのですが,それにもとづいて実トラフィックを発生させた例はすくないようです. それにどれだけの意味があるのかは検討が必要ですが,やってみる価値はあるとおもいます.
そうやって評価した結果の一部を研究会などで発表してきたわけです. 期間がかぎられていたので,かならずしも目標どおりにはいきませんでしたが,それでも一応,QoS 保証法の設計からプログラム開発,客観評価・主観評価という一連のプロセスを 1 年間でなんとか,まわしました. もちろん,それができたのは,おおくのひとの協力があったからにほかなりません (論文には謝辞にそれらのひとの名前が書いてありますが,ここでは省略させてもらいます). そして,客観評価と主観評価のそれぞれにおいて,ある程度の成果をえることができました. このうちとくに主観評価については書いておきたいエピソードもあるのですが,それについてはべつの項目,あるいは別の機会にゆずることにします.
]]>こういう,研究テーマ選択における,あまいかんがえかたは,その後しだいにあらためていきましたが,まだ十分ではなかったようにおもいます. 1990 年代に私は軸づけ検索を研究しましたが,これはもともと百科事典のために開発したものであり,その線にそって製品化されました. しかし,これも利益をうみませんでした. つぎに手がけた研究はポリシーにもとづくネットワーキングと QoS 保証でした. これは私が提案したものではありません. 製品化されましたが,予想どおりにはいかず,やはり利益をうみませんでした.
結局,これまで私がてがけた研究で会社に利益をもたらしたものはほとんどありません. その出発点がバブル時代だったとおもっています. しかし,こうやって,しだいに (おそすぎたかもしれませんが) テーマのえらびかたに関しても訓練されてきたようにおもいます. もう会社で仕事ができる年月はあまりながくないのですが,社会と会社に貢献できる研究ができる可能性はたかまっているようにおもいます.
]]>これらのかんがえかたのうちのどちらをとったほうがよいかは,ときとばあいによります. しかし,私自身は基本的なかんがえかたとして,コンピュータには人間ができないことをやらせるべきだとかんがえています. これに対して,私がこれまで話をしてきたおおくのロボット研究者はロボットに人間とおなじように仕事をさせた,あるいは人間ができる仕事をよりよくやらせたいとかんがえていました. 人工知能や認知心理学のおおきな目標として人間の知的な能力を解明することがあるので,その実現のためにはこのようなアプローチがよいでしょう. しかし,工学者である私にとっては人間が不得意な部分をコンピュータやロボットにやらせることによって,全体としてよりよく仕事ができるようにすることが目標でした.
こうしたかんがえかたが軸づけ検索や voiscape の研究にどのように反映されたかについては 「ユビキタス・コンピューティングとエージェント指向コンピューティング」 に書いたので,ここではくりかえしません.
2007-10-11 追記:
「人間にできない部分をおぎなうコンピュータ」 は,同時に 「人間の能力をひきだすコンピュータ」 であるべきです.
つまり,人間ができる部分は人間がやるようにするわけなので,そこを人間がうまくやれるようにしないと,ボトルネックになってしまいます.
人間がやる部分についてもできるだけ人間をたすけることによって,パフォーマンスを最大化することができます.
エージェント指向コンピューティングの思想は現在でもコンピュータ科学・技術の世界におけるひとつの主要な思想です. このかんがえかたにおいては,ひとがエージェントに仕事をたのんで楽をすることをかんがえます. 「エージェント」 ということばは 「代理者」 つまり仕事をかわってやってくれるひとということですが,秘書のようなものだとかんがえればよいでしょう. 自分ではできない仕事を秘書にかわってやってもらう. やってもらうことによって秘書の能力はさらにたかまるでしょうが,依頼者は学習しない,したがってバカになってしまうかもしれません. これに対してユビキタス・コンピューティングは個人のパワーを道具によってたかめることをめざしていました. パワーがたかまれば,むずかしい仕事が自分でできるようになります. つまり,人間の能力をよりよく発揮できるようにします. 仕事をやる過程で学習して,そのひとの能力がたかめられます.
仕事の種類や,ときとばあいによってエージェント指向とユビキタスのうちどちらがよいかはかわるでしょう. しかし,抽象的にかんがえるかぎりは,(誇張的な表現ですが) 私には人間をバカにするエージェント指向より人間の能力をたかめるユビキタスのアプローチのほうが魅力的におもえます. そのため,私はこれまで研究テーマのうえで 「知的なエージェント」 をあつかったことは一度もありません. なにか判断したり選択したりする必要があるとき,エージェントがそれをやるのでなく,人間が判断や選択をしやすい状況をつくることをめざしてきました.
軸づけ検索においては 検索結果を整理してユーザにみせることによって,ユーザがよりおおくの情報から選択したり,情報どうしの関係をみつけたりすることができるようにすることをめざしました. また,voiscape においてはさまざまな音源のなかからほしいものを,自動的にすなわち知的エージェントがえらびだすのではなく,おおくの音源のなかからユーザが選択できるようにすることをめざしました. これらの研究はまだ十分な成果をあげているとはいえませんが,これらの 「ユビキタス」 にもとづくかんがえかたは,これからも追究していく価値があるものだとおもっています.
* ワイザーがユビキタス・コンピューティングとエージェント指向コンピューティングとを対立的にかんがえていたといういいかたは,もしかすると誇張かもしれません. Weiser [Wei 93] にはつぎのような表現があります.
Unlike the intimate agent computer that responds to your voice and is a personal assistant, ubiquitous computing takes place primarily in the background. Whereas the intimate computer does your bidding, the ubuquitous computer leaves you feeling as though you did it yourself.
しかし,ワイザーがこれ以上の対比的な表現をつかっていたかどうかについては私はしりません.
[Wei 93] Weiser, M., "Hot Topics: Ubiquitous Computing", IEEE Computer, Vol. 26, No. 10, pp. 71-72, October 1993.
]]>製品を開発する技術者は設計・製造に必要な知識を獲得して,実際にそれを設計します. 企業研究者もそれにちかい作業をおこないますが,現在の製品の開発に埋没することなく,より応用のきく技術を開発する必要があります. そのためには,製品開発のなかでぶつかる課題を分析して,より普遍的な問題をみつけだす必要があります. そのためには,ぶつかった課題を数理的にモデル化 (抽象化) することが有効です. 適切なモデルをみつけて,それにあった手法を適用する必要があります. 適切なモデルをみつけるためには,さまざまな数理モデルを知っている必要があります. 重要なモデルは大学で学習しますが,さらに学習をかさねることによって,よりさまざまな状況に対応することができるようになります. 研究にかぎらず企業での仕事の際に問題をモデル化しなさいということを,私も東大在学中に講義をきいたことがある,すでになくなられた米田信夫先生がプログラミング・シンポジウムでおっしゃっていたのをおもいだします.
たとえば,私は入社してまもなくベクトル計算機のための Fortran コンパイラの開発 (ベクトル / 並列計算機のためのプログラミング言語処理) に従事しましたが,ここでプログラムのベクトル化 (並列化) が可能かどうかを判定するアルゴリズムを開発して,実際にコンパイラにくみこみました (Compiling Algorithms and Techniques for the S-810 Vector Processor). この課題は入社したての私にとって適切なものでした. モデルとしてはコンパイラの本によく書いてあるデータフロー解析のためのプログラムのモデル (基本ブロックを単位とするグラフ) をつかうことができました. 既存のコンパイラにおいてすでに基本ブロックへの分割がなされていて,かつ手順としては通常のデータフロー解析の手順をあてはめればよかったので,私の仕事はほとんど各基本ブロックにわりあてるべき変数をみつけることだけでした. さいわい,データフロー解析の手順を適用することによってベクトル化可否がこたえとしてえられるような変数をみつけることができました.
つぎの Fortran コンパイラの開発 (スカラー計算機のためのプログラミング言語処理) においても,データフロー解析のモデルがやくにたちました (大域配列データフロー解析法) が,詳細はここでは省略します. この開発ではまた,整数論やそれをとくためのディオファンタス方程式をモデルとしてつかいました. これらもまた,まえのコンパイラをてがけていたときにしいれた知識です.
最近ではこれほど数学との関係が明確なモデルがつかえなくなって,やや,みとおしのわるい仕事をするはめにおちいっています. もしかすると,もっとちがったモデルを学習するべきなのかもしれません.
]]>非決定論は自由意志や時間論とも関係しています.決定論的な世界には意志によってかえられるものがありませんし,時間の矢つまり一方向にすすむという性質がありません. 私は高校生のころから時間というものに興味があって,時間論の本をいろいろ読んでいました. それよりずっとあとになってからですが,プリゴジンの理論,あるいは自己組織の理論やベルクソンの哲学に興味をもちました. 非決定論という意味ではもちろん量子力学とおおいに関係があります. 理論的な関係は把握していませんが,インフレーション宇宙論などとも関係しているようにおもいます. 上記のような哲学的な問題はやはり非決定論的 / 確率的な動作とむすびついています.
なお,上記のような考察の一部は「コンピュータによる自己組織系のモデルをめざして」のなかでもっとくわしく展開しています.
]]>このころはまだ現在の GUI の技術が確立されていたとはいえないとおもいますが,それでも,現在おおくの GUI ライブラリがそなえている機能が Macintosh Common Lisp にはありました. テキストボックスや各種のリスト,メニュー,ウィンドウ等々です. しかし,私自身はそれらの静的なしかけだけでは満足せずに,もっと動的に変化するインタフェースを実現しようと悪戦苦闘し,その結果たいした成果もだせずにおわってしまいました.
この不毛な経験のため,もうユーザインタフェースに手をだすのはやめようといったんはおもいました. そのためしばらくはそこからはなれていましたが,百科事典の検索をデモするために,ついにふたたびそこに手をだしてしまいました. このとき (1997 年) にはすでに Web インタフェースのための基本的なしかけ,すなわち CGI の技術が確立していて,それをつかえば VIPS を開発したころよりずっと容易に GUI をつくることができるようになっていました. スタイルシートがまだなかったので,みばえをよくしようとおもうと容易でなかったのですが,そこまでやろうとはおもいませんでした. CGI のためには Perl をつかうのがよいときいたので,そのために Perl をおぼえました.
こうしておぼえた Perl + CGI による Web インタフェース作成術は,その後たびたびつかっています. DEPS というポリシーサーバのインタフェースにもつかっていますし,発表はしていませんが voiscape の管理インタフェースや実験用インタフェースにもつかっています.
Java をつかって GUI をつくろうとしたこともありましたが,なかなかおもうようにプログラミングできないので,やめてしまいました.
最近では Perl + CGI というしかけはだいぶ,ふるびてきたので,そろそろもっとあたらしい技術にのりかえようとかんがえていますが,それでもチョロッと GUI をつくるには便利なので,あいかわらずつかっています.
]]>軸づけ検索のひとつの技術的要素は全文検索ですが,高速性を要求される全文検索のプログラムも Perl で書きました.CPU 時間よりはディスク・アクセスの時間のほうが問題なので,インタプリタで実行される Perl であっても,プロトタイプとしてはなんとかたえられるレベルにありました. むしろ,インデクスを格納するのにつかった GNU DBM がおそくて,検索にけっこう時間がかかるばあいがありました.
検索・組織化のプログラムだけでなく,検索に使用するインデクスをあらかじめ生成するのにも Perl をつかいました. ここでは,百科事典のテキストから年代表記や地名などを抽出するのにパターンマッチ機能が威力を発揮しました. 「テーマ検索」の製品における検索ではより高速性がもとめられるので Delphi をつかいましたが,そこでもインデクスの生成には Perl をつかっていました.
その後すっかり仕事がかわってルータにコマンドをたたきこむ QoS ポリシーサーバなどを開発するようになりました (ポリシーにもとづくネットワーキングと QoS 保証) が,このときも,プロトタイピングには Perl をつかうのが便利でした.理由は軸づけ検索のときとおなじでした.つまり,ルータの CLI (コマンドライン・インタフェース) がはきだす文字列を解析するには Perl のパターンマッチ機能が便利であり,また GUI (ユーザインタフェース) には CGI をつかうのが便利だったということです. このころには Python とか Ruby とか,Perl よりよくできた部分があるスクリプト言語がつくられていましたが,なれた言語をてばなすことができず,いまだに Perl をつかっています.
その後,voiscape についてはおもに Java や C++ をつかいましたが,voiscape サーバのための管理インタフェースなどには Perl をつかっています.最近はまたポリシーサーバなどをあつかっているので,Perl が中心になっています. QoS の主観評価をするときも被験者やオペレータのための GUI を Perl で書いています. 最近はカッチリと Web インタフェースをつくるには Struts や ASP.NET といった Web アプリケーション・フレームワークをつかうことがふえてきています.私も製品にちかいプログラムの開発ではそれらをこころみてはいます.しかし,プロトタイピングや短期間だけつかう GUI を開発するには Perl のほうが便利です.
]]>私が入社して最初にとりくんだ仕事はスーパーコンピュータ (ベクトル計算機) で Fortran プログラムが実行できるように変換し最適化する方法を開発すること (ベクトルのためのプログラミング言語処理) でした. この仕事は会社が開発していた S-810 というスーパーコンピュータ製品に直結するものでした. 当時,私はまだ論文の書きかたも十分にマスターしていなかったので,研究成果を十分なかたちで世におくりだすことはできませんでした. しかし,この研究は研究リーダーだった安村さん (現慶応大教授) 中心の ICPP の論文 につながり,また情報処理学会全国大会で発表しているので,(事業収支はともかくとして) ビジネスと研究を両立させることができたということができます.
論理 / 記号 ベクトル処理の研究は,Fortran のために開発した技術を非数値処理 (記号処理) にいかそうという意図をもって,私が会社に提案してはじめた研究です. ビジネス上の目的としては,Fortran コンパイラと同様にベクトル計算機の適用範囲をひろげることにありました. Fortran とはちがってベクトル計算機に適用することがむずかしい論理型言語や記号処理があつかえるようにする必要があったので,たかい成算があったわけではありません. また,目標が達せられたとしても,それほどおおきな利益がえられるともかんがえてはいませんでした. つまり,会社の技術力をたかめることが間接的にビジネスの拡大につながることを期待していました. しかし,結果的にはそういう意味においてもビジネス的に成果をあげたとはいえませんでした.
化学的計算のモデル (CCM) も私が会社に提案してはじめた研究です. 私の研究テーマのなかでももっともビジネスからとおいテーマでした (つまり,ビジネスとの関係を説明できなかった) が,提案時はまだバブルがはじけるまえであり,時代的にこのようなテーマでもみとめられたのだとおもわれます. このテーマはその後,私が国家プロジェクトの RWCP (Real-World Computing Partnership) に出向して,そこに場をうつして継続しました. これは,私が提案したわけではなく,あるいきさつがあってそうなったのですが,バブルがはじけたあとの先物研究のあつかいとして妥当だったとかんがえられます.
ランダムな非同期セル・オートマトン (RACA) は CCM の副産物だったのですが,CCM が実用的な計算をめざしたモデルだったのに対して,これは複雑系的な興味による研究であり,実用はまったくかんがえていませんでした. RWCP にいたので,会社のビジネスについてかんがえる必要はありませんでした.
RWCP から会社に復帰したときには,もはやビジネスにつながりにくい研究をすることはかんがえにくくなっていました. 電子商取引や,AltaVista のような Web の検索エンジンが注目されるようになっていて,Web 上の検索やデータマイニングというような方向の研究を模索しましたが,結局はちょうど社内でもちあがっていた百科事典の仕事をすることにおちつきました. 百科事典の検索は Web の検索とはちがいますが,共通する部分もあります. 単純な項目・索引検索や全文検索の技術はすでにあったので,もっとおもしろい検索法を開発することが目的であり,研究とビジネスの目的がかさなりあっていました. そこでかんがえだしたのが軸づけ検索 (テーマ検索) でした. しかし,結局は単純な検索より人気のたかい検索法に発展させることはできず,ビジネスとして成立はしたものの,会社の利益に貢献することはできませんでした.
その後,ネットワークの仕事をあたえられて,おもわぬ方向転換をすることになりました. ポリシーにもとづくネットワーキングと QoS 保証というテーマは IPA (当時の名称は情報処理振興事業協会) の仕事としてはじまりましたが,やがて HP 社との協業 (collaboration) による PolicyXpert というポリシーサーバ製品の開発につながっていきました. QoS ポリシーの研究をはじめて以来,私のおもな興味は「ポリシーのくみあわせ」というところにありましたが,それがこの製品において重要だとかんがえたため,研究とビジネスの目的をあわせて達成しようとしました. HP 社側は研究所がからまなかったので,私と仕事をしなければたぶん一生,論文の著者になることはなかったであろう HP 社のプログラマと連名でジャーナル論文まで書くことになりました.
仮想の "音の部屋" にもとづくコミュニケーション・メディア voiscape も私が会社に提案してはじめた研究開発ですが,このときには研究とビジネスとの両立をめざし,かつ私としてはビジネスのほうに力点をおいていました. 他の予算がとれなかったということもありますが,いわゆるインキュベーション的なやりかたをとりました. いまのところビジネスとしてはうまくいっているとはいえず,かなりの赤字をだしてはいますが,ゼロではない実績があります.
]]>