Kanada, Y., 2nd IASTED International Conference on Communication and Computer Networks (CCN 2004), 2004-11.
[ English page ]
[ 論文 PDF ファイル ] [ OHP PDF ファイル ]
要約:
A new voice communication medium, which the author calls "voiscape", will
probably appear in near future. Voiscape shall have much improved user
interface than the conventional voice communication systems, i.e.,
telephone and conference systems, and be based on the IP-based
conferencing and spatial audio technologies. The author has developed
a prototype toward voiscape, which has made a step toward solving two
problems of the conventional systems i.e., complicated and restricted
conference control and lack of crossed-over multi-context support, by
introducing two features. The first function is the virtual-location
based communication; i.e., the users can talk with other users and move,
in a way similar to face-to-face conversation, in a virtual auditory space
created by spatial audio technology without explicit session and floor
control. The second function is personalized policy-based communication
control; i.e., the users can specify communication policies that protects
their privacy and reduce required resources. This function is enabled by
a distributed policy-arbitration mechanism. Experiments showed that the
basic mechanisms and the policy-based control with a simple policy
worked well.
研究テーマ紹介:
voiscape
キーワード:
voiscape, 会議室管理, 音室管理, 仮想コミュニケーション空間, 仮想コミュニケーション場, 仮想空間, 仮想の場所, 仮想場, バーチャル空間, ヴァーチャル空間, バーチャル・スペース, ヴァーチャル・スペース, バーチャル・プレース, バーチャル・プレイス, バーチャルスペース, ヴァーチャルスペース, バーチャルプレース, バーチャルプレイス, コミュニケーション・メディア, 音声コミュニケーション, 多声会話, 音声会話, 立体音響, 3次元オーディオ, 三次元オーディオ, 3Dオーディオ, 3次元サウンド, 三次元サウンド, 3Dサウンド, 3D音響, 3次元音響, 三次元音響, JMF, Java, Java 3D, Java Media Framework, Javaメディア・フレームワーク, Javaメディアフレームワーク

」 と 博士論文 「ベクトル記号処理法とその論理型言語プログラムへの適用
」 を Kindle 本として出版しました. 後者に関しては,これまで公開していた PDF 版からぬけおちていた付録もおぎないました.

 Abstract: Instead of printing layer by layer, thin 3D objects can be printed in better quality (without seams between layers) by printing helically or spirally by fused deposition modeling (FDM). When printing helically or spirally, the amount of extruded filament can be modulated using a bitmap; that is, “zero” in bitmap means “thin” and “one” means “thick” (or vice versa). This process generates a thin object, such as a sphere, pod, or dish, with a bitmapped picture or characters. A typical example is a globe, which is printed using a bitmapped world map.
Abstract: Instead of printing layer by layer, thin 3D objects can be printed in better quality (without seams between layers) by printing helically or spirally by fused deposition modeling (FDM). When printing helically or spirally, the amount of extruded filament can be modulated using a bitmap; that is, “zero” in bitmap means “thin” and “one” means “thick” (or vice versa). This process generates a thin object, such as a sphere, pod, or dish, with a bitmapped picture or characters. A typical example is a globe, which is printed using a bitmapped world map.

 要旨: When creating shapes by using a 3D printer, usually, a static (declarative) model designed by using a 3D CAD system is translated to a CAM program and it is sent to the printer. However, widely-used FDM-type 3D printers input a dynamical (procedural) program that describes control of motions of the print head and extrusion of the filament. If the program is expressed by using a programming language or a library in a straight manner, solids can be created by a method similar to turtle graphics. An open-source library that enables “turtle 3D printing” method was described by Python and tested. Although this method currently has a problem that it cannot print in the air; however, if this problem is solved by an appropriate method, shapes drawn by 3D turtle graphics freely can be embodied by this method.
要旨: When creating shapes by using a 3D printer, usually, a static (declarative) model designed by using a 3D CAD system is translated to a CAM program and it is sent to the printer. However, widely-used FDM-type 3D printers input a dynamical (procedural) program that describes control of motions of the print head and extrusion of the filament. If the program is expressed by using a programming language or a library in a straight manner, solids can be created by a method similar to turtle graphics. An open-source library that enables “turtle 3D printing” method was described by Python and tested. Although this method currently has a problem that it cannot print in the air; however, if this problem is solved by an appropriate method, shapes drawn by 3D turtle graphics freely can be embodied by this method.


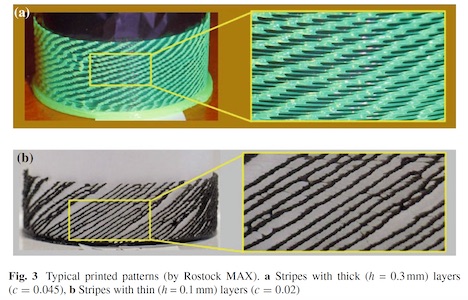
 要旨: 3D printing technology usually aims at reproducing objects deterministically designed by 3D CAD tools; however, the author has discovered that 3D printing can also generate self-organizing patterns similar to stochastic (or randomized) 1D cellular automata (CA). A method for generating patterns similar to randomized 1D or 2D CA by using a fused deposition modeling 3D printer is thus proposed. With constant head motion and constant filament extrusion and without explicit randomness, this method generates very fine emergent patterns with natural fluctuation. By means of this method, each time a different pattern is generated. In addition, a computational CA model that simulates the above process is also proposed. The proposed method will open a new horizon of 3D printing applications.
要旨: 3D printing technology usually aims at reproducing objects deterministically designed by 3D CAD tools; however, the author has discovered that 3D printing can also generate self-organizing patterns similar to stochastic (or randomized) 1D cellular automata (CA). A method for generating patterns similar to randomized 1D or 2D CA by using a fused deposition modeling 3D printer is thus proposed. With constant head motion and constant filament extrusion and without explicit randomness, this method generates very fine emergent patterns with natural fluctuation. By means of this method, each time a different pattern is generated. In addition, a computational CA model that simulates the above process is also proposed. The proposed method will open a new horizon of 3D printing applications.




