量の仮想化と質の仮想化
仮想化に関してはさまざまな分類がありうるが,ひとつの分類は量の仮想化と質の仮想化である.
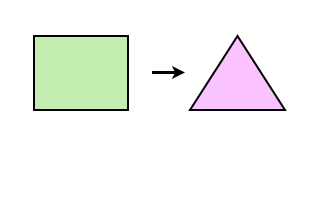
- 質の仮想化 (qualitative virtualization)
- 質をかえるような仮想化である.
質の仮想化によって仮想化前と量はかわらない (かもしれない).
- 量の仮想化 (quantitative virtualization)
- 数量をふやす,またはへらすような仮想化である.
量の仮想化によって仮想化前と質はかわらない (かもしれない).
これらの仮想化をくみあわせることができる. つまり,量と質を同時に仮想化することができる.
分割型仮想化と融合型仮想化
量の仮想化はさらに分割型と融合型とにわけることである.
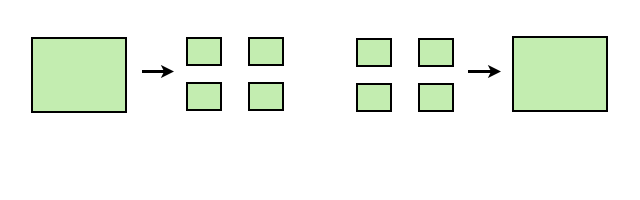
- 分割型仮想化 (dividing virtualization)
- 1 個のコンピュータやネッ トワークのなかに複数の仮想的な コンピュータやネットワークをつくる.
- 融合型仮想化 (fusing virtualization)
- 複数のコンピュータやネッ トワークを仮想的に 1 個のコン ピュータやネットワークにみせる.
図 分割型仮想化 (左) と融合型仮想化 (右)

現在, 実用化・実験されている仮想化技術のおおくは分割型の仮想化を実現している. すなわち,融合型の仮想化は比較的かぎられている.
コンピュータの仮想化
コンピュータの仮想化に関しては,融合型の仮想化はほとんどないとかんがえられる.
最初にのべたように仮想化には量に関するものと質に関するものとがある. 最近話題になるサーバ仮想化は量的な仮想化をしている. つまり,それによって物理コンピュータとおなじアーキテクチャの仮想コンピュータが複数個つくれる. たとえば Intel CPU 搭載の物理コンピュータから, 複数の Intel 仮想マシンがつくれる.
一方,コンピュータを質的に仮想化することもできる. 物理コンピュータとはことなるアーキテクチャの コンピュータをつくる. その例として,つぎのようなものがある. 最初の 2 つが比較的ちかい関係にあり,最後の 2 つもそうである.
- トランスメタ社の Crusoe, Efficeon: Intel x86 の命令を独自の命令 (VLIW) に 翻訳して実行する CPU (2002-2004 年ごろ).
- Intel Pentium Pro (とそれ以降の CPU): 複雑な x86 命令を単純な RISC 風命令に ハードウェアで翻訳して実行する.
- P コード・マシン: コンパイラの仕事が容易に なるような仮想マシンを定義して,シミュレータで 実行する. N. ヴィルトの Pascal P が有名.
- バイトコード・マシン: Smalltalk, Java などの言語は バイトコードとよばれる仮想的な機械語を実行する仮想 マシン (シミュレータ) で実行される.
ネットワークの仮想化
ネットワークの仮想化においては分割型の仮想化と融合型の仮想化の両方がおこなわれている.
- 分割型の仮想化
- ネットワークに関しても分割型の仮想化のほうがひろくつかわれている. その例として VPN (仮想プライベート・ネットワーク) や VLAN がある.
- 融合型の仮想化
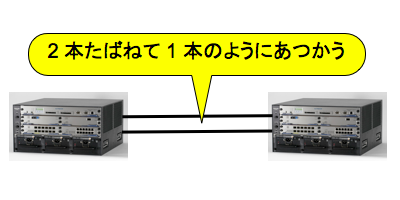
- 融合型の仮想化の例としてリンク・アグリゲーションをあげることができる. リンク・アグリゲーションにおいては,複数の物理リンクをたばねて 1 個の仮想的なリンクにみせる. また,Juniper などのベンダは複数のスイッチをたばねるしかけを製品にとりいれている.
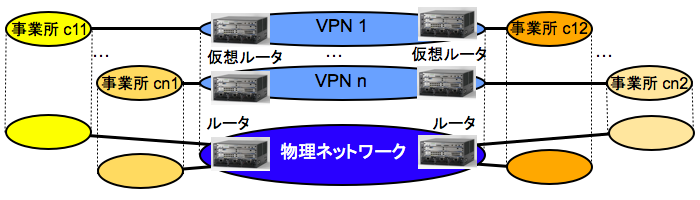
VPN は仮想化されたプライベート・ネットワークである. プライベート・ネットワークとは,インターネットのようなパブリックなネットワークからきりはなされた,もしくは直接はアクセスできないネットワークである. 1 個のプライベート・ネットワークを専用のハードウェアすなわちルータ,スイッチ,リンクなどによって構成することも可能だが,それにはおおきなコストがかかる. コストを低下させるには,仮想化してハードウェアを共用すればよい. すなわち,ルータやスイッチを分割型の仮想化によって複数の仮想ルータや仮想スイッチに分割し,同時にリンクも分割型の仮想化によって複数の仮想リンクに分割する.
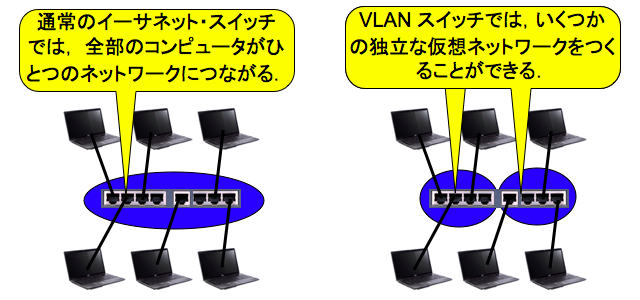
VLAN はイーサネットを分割型の仮想化によって分割する. この場合もスイッチとリンクとがそれぞれ仮想化される.
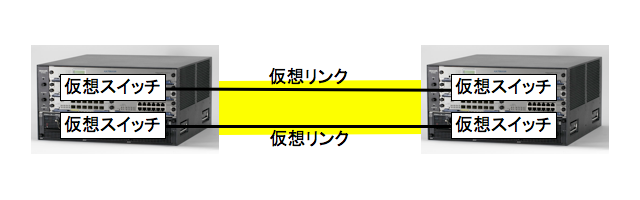
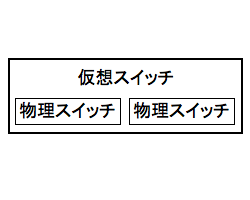
このうちスイッチの仮想化によって,1 個のスイッチを複数の独立なスイッチのようにつかうことができる. また,リンクの仮想化によって,1 本の物理リンクを仮想的に複数のネットワーク (イーサネット) で使用できる. このようなリンクをトランクリンクという. トランクリンクでは VLAN タグによって仮想ネットワークをくべつする.